Know Thyself
It’s inevitable that over time I’m going to repeat myself here (including post titles). When I’m aware of potential similarities, I try to embed links back to those prior posts. A while back I noted an idea of building a thematic map of all my posts, but I wasn’t sure how to go about doing so. Now that I’ve learned some about embeddings, it was time to try my hand at it.
You can find the code I wrote to accomplish all of this on GitHub. I was inspired by the clustering section of the OpenAI cookbook, but took considerable liberties rewriting the code there, as I’m not a huge fan of typical data science code examples (they’re suitable for notebooks, perhaps, but rarely include meaningful names or breakdown into logical functions).
First, I had to actually fetch all the post content. I briefly toyed with the WordPress REST API, but couldn’t figure out how to enable it. No worries, though, RSS to the rescue! Unfortunately it’s XML, and I fiddled a bit with using lxml to parse the it, but stumbled upon feedparser which abstracted the details. Awesome!
Since it’s the de facto standard for Python data science, I loaded the posts into a pandas DataFrame. I’m still working on my fluency with pandas, numpy, scikit, and matlibplot, amongst other common tools, and I’m grateful for any opportunity to get their power under my fingers.
To compute embeddings for each post, I used the OpenAI API with the text-embedding-ada-002 model. It’s not good to store API keys in code; for local scripts I store all mine in the MacOS keychain using keyring. Nice and easy.
Since OpenAI usage costs money, I don’t want to repeatedly call the API with identical inputs if I don’t have to. That’s where cachier comes in (a library I help maintain) so results can be transparently saved to disk for subsequent use.
Once I had the embeddings, I used K-means clustering to group posts into common themes, and then t-SNE to reduce the dimensionality and produce a visualization of the clusters. To produce a summary of the theme of each cluster I took a sample of posts from each and shoved them into GPT4.
To start I tried using 2 clusters, which produced the following distribution:
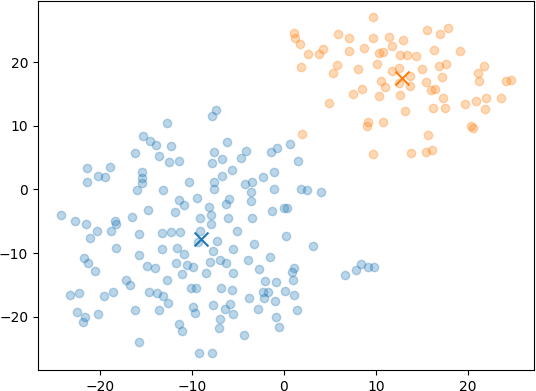
Pretty interesting that there’s a natural grouping going on. Here’s the themes and sample posts:
Blue Posts
The theme of these posts is the author’s personal and professional experiences with technology, education, open-source contributions, ethical considerations, and the impact of travel and diversity on personal growth and the tech industry.
- School’s In Session
- Get In The Arena
- Wants What It Wants
- The Butterfly Effect
- Zeros And Ones
- It’s A Small World
- Living On A Jet Plane
- Be Kind, Not Right
- Worth A Million Words
- Leave No Trace
Orange Posts
The theme of these posts revolves around the reflections, experiences, and insights of a software developer navigating the challenges and nuances of the tech industry.
- Say Hello
- Phantom Fix
- Save Something For Grace
- Hello world!
- Trump Card
- To Alcohol and WiFi!
- Developers Have Personalities
- Covfefe
- Thinking In Future Tense
- Be A Polyglot!
Of course I had to try with a variety of different numbers of clusters, so I reran with 3, 5, and 8 clusters as well (anyone see a pattern there?)
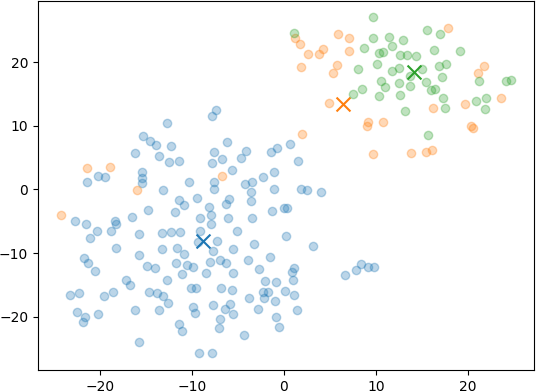
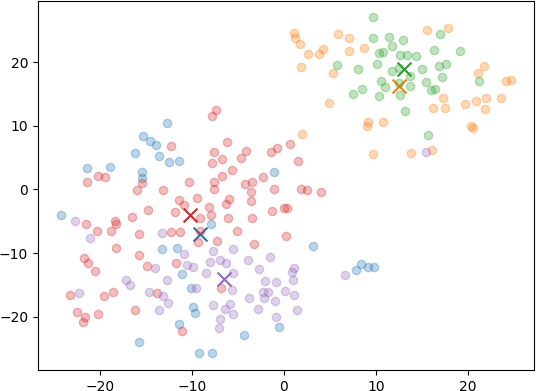
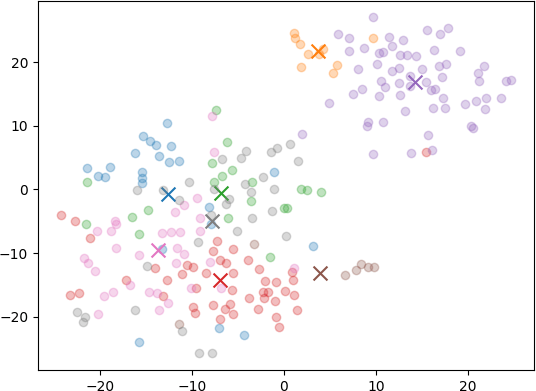
Of those graphs, to my eye the 5 cluster one seemed the best balance between having enough distinct themes without starting to look too arbitrary. Here’s the summarizations for it:
Blue Posts
The theme of these posts is the author’s personal and professional experiences, challenges, and insights related to technology, software development, and working within the tech industry.
- Amongst The Silos
- It’s Not Personal
- Security Sunday
- Testing, Testing, 1, 2, 3
- Not Just Lip Service
- Getting Warmer
- Just Do It
- Can’t Fight This Feeling
- Left Hand, Meet Right Hand
- It’s Been Awhile
Orange Posts
The theme of these posts revolves around the challenges, insights, and anecdotes from the world of software development and engineering management.
- To Alcohol and WiFi!
- Slimming Down
- Phantom Fix
- Even If It’s Broke, Don’t Fix It
- Balance Of Probability
- This Is A Post
- Ain’t No User Here
- Winging It
- Writing On A Saturday?
- High-Powered Foot Assault Rifle
Green Posts
The theme of these posts is the multifaceted nature of software development, encompassing the importance of maintaining code quality, the broad skill set required for effective development, and the challenges and responsibilities that come with the profession.
- Eschew Filler
- Scouts Honor
- The Other Full Stack
- Dirty Work
- It’s Elementary
- Tyranny Of The Urgent
- Jud’s Law
- The Devil Is In The Details
- Busy, Busy, Dreadfully Busy
- Harder Than It Looks
Red Posts
The theme of these posts is the reflection on and sharing of personal experiences, insights, and best practices related to software development, including contributing to communities, understanding abstractions, effective communication, and professional growth within the tech industry.
- On The Brink
- Turtles All The Way Down
- Isn’t It Ironic?
- Mount Rushmore
- Ketchup
- Takin’ Care Of Business
- Perdido En La Traducción
- Eye Of The Beholder
- Hitting The Links
- Slacker Part Deux
Purple Posts
The theme of these posts is the author’s personal reflections on their experiences, interests, and philosophies related to their career, hobbies, and life choices.
- Because I Can’t Not Make
- Next To Godliness
- Half The Battle
- Cerberus
- Tools Of The Trade
- Forth Eorlingas
- Little Light Of Mine
- On The Turning Away
- Not Forgotten
- Whoever Will Lose Their Life
What’s next? I’d like a quantitative way to evaluate the quality of the theme clustering and summaries produced. There’s a lot of non-determinism in the functions used here, and with some twiddling I bet I can produce improved results. I’ve got some ideas, but will save them for a future post.